
Latent Dirichlet Allocation (LDA) and Google
The study of the algorithm of LDA (Latent Dirichlet Allocation) is the new trend among webmasters. He raises a secrecy of the algorithm of the Google search engine and partly explains how the sites are selected in its results pages.
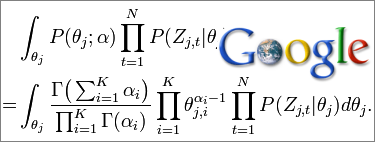
This trend has been launched by Seomoz.org when it proposed a tool to evaluate a Web page by applying this algorithm. This tool provides a score of relevance to a query, if it is more relevant it is supposed to reach the top in results of search engines.
The validity of the score has been verified experimentally.
The word Dirichlet comes from Johann Peter Gustav Lejeune Dirichlet, a German mathematician who studied in France and rubbed shoulders with French mathematicians of the 19th century, who has done work in the field of complex analysis and probability laws.
The LDA algorithm was described for the first time by David Blei in 2003, who published an article available on the site of the Princeton University.
A document entitled Online Inference of Topics with Latent Dirichlet Allocation published by the University of Berkeley in 2008 compares the relative merits of two algorithms for LDA.
What is LDA?
The LDA has an essential purpose of classification, it can associate a context to a document based on words contained in this document, words which individually might belong to different contexts.
For example the word robot can refer to a program (robot of search engine) or a machine (humanoid robot). The analysis of words near that word on a page can tell if the page or paragraph is about software or machines.
Search engines define a context from a query and the habits of the user, the pages previously visited. They still have to find pages containing the keywords of the query, but in the context of the user and for this purpose LDA is applied to pages in the index.
The algorithm is a Bayesian model, it aims to determine the probability of a hypothesis. Since this it is to associate a keyword or a group to a topic, the assumption is the topic, and there is several in competition.
Bayesian inference is used elsewhere in computer science and it is the base of bots for example to create a filter against spam.
Training a search engine algorithm in the same manner may be more effective than using a preset code.
Citation (Griffiths and Steyver):
Latent Dirichlet Allocation is a powerful learning algorithm for automatically and jointly clustering words into topics and documents into mixtures of topics. It has been successfully applied to model change in scientific fields over time .
LDA and optimization
SEOmoz created the tool after having found a correlation between the results of Google and this algorithm. The conclusion is that Google incorporates the LDA in its algorithm, which actually is broader and incorporates many other criteria.
The LDA is essentially based on the content. Google's algorithm contains criteria on the content, but also independent of the criteria, including the number of links pointing to a page.
Experience shows that the first sites in results pages of Google have more relevant content than those which come after.
To best use this algorithm, it is better to strengthen the context of a page from the query that we want to answer by adding words related to the keywords already in connection with this query.
But some pitfalls should be avoided...
What LDA is not:
- This is not a criterion of density of keywords.
It is unnecessary to accumulate the same keywords in the hope of seeing better positioned in the SERPs. They only serve to find the context of the page and this is the choice of words that counts and not the number. - This is not a dictionary of synonyms.
These are the associations between words representing different things but interrelated, that counts. It is also unnecessary to accumulate synonymous to a word to the LDA, however that may be useful more generally.
The repetition of a keyword brings nothing, but repetition of context to the reverse may be useful. Groups of keywords on a subject, eg programs, or machines, found several times in the page, can improve its position.
Documents and code
- LDA implementation on Hadoop by Yahoo!. Code on GitHub.